
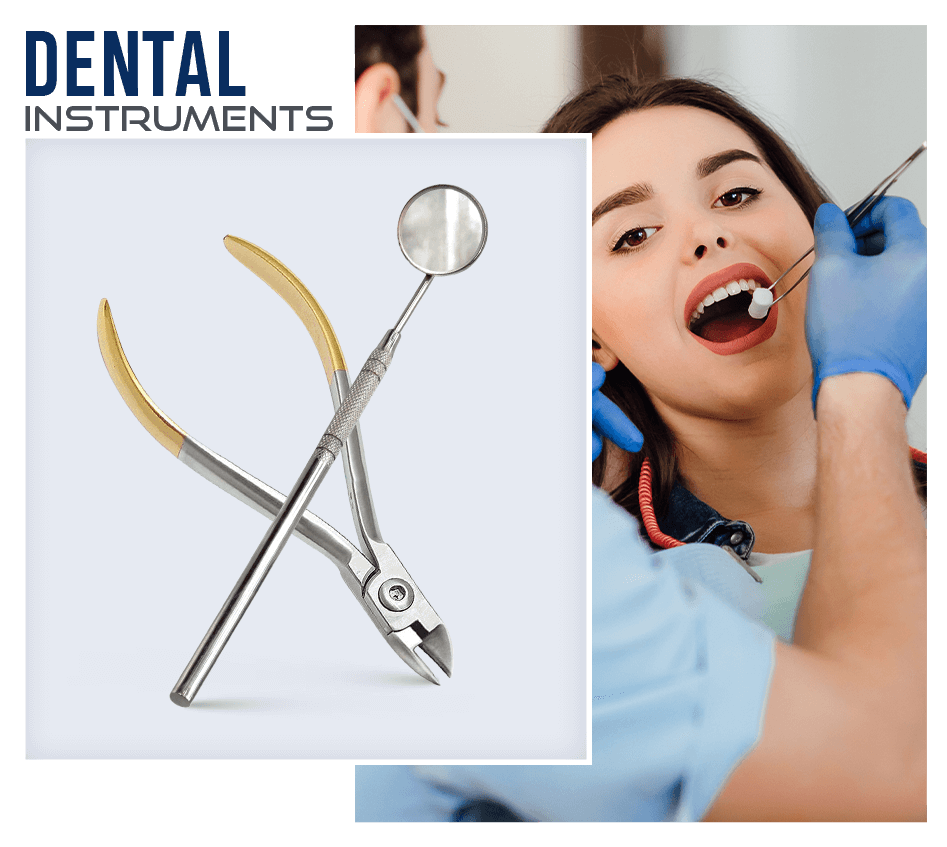


We Have Experienced Workers.
Our company is staffed with experienced professional workers who have experience over 20 years in instruments manufacturing.
Quick Response/Reply.
We try to reply your inquiries as soon as possible maximum within 12 hours.
We Are Improving Everyday.
We are always looking to improve every aspect of our business with Market DemandS
Where we are exporting our items
We are already exporting our product to big countries like USA, UK, Japan & Germany.







Vavada Casino – популярная игровая платформа, предлагающая множество видеослотов и турниров. С момента открытия, казино завоевало доверие пользователей благодаря разнообразию игр, бонусам и удобному интерфейсу. Платформа имеет лицензию Curacao, что подтверждает ее надежность и авторитет.
На Vavada Casino легко ориентироваться благодаря современному дизайну. Здесь можно найти видеослоты, настольные игры и live-игры от таких провайдеров, как Rival Gaming, 1×2 Gaming, Betsoft и PlayTech. Для пополнения и снятия средств доступны различные способы оплаты, включая кредитные карты, электронные кошельки и банковские переводы. Защита финансовых данных обеспечивается передовыми методами шифрования.
Преимущества Vavada Casino:
Рабочее зеркало Vavada позволяет игрокам обходить блокировки и продолжать игру. Зеркало предлагает тот же интерфейс и возможности, что и основной сайт, обеспечивая безопасность и конфиденциальность личных данных. В случае проблем с доступом к основному порталу, рабочее зеркало является отличным решением.
Регистрация на Vavada проста и бесплатна. После создания аккаунта пользователи могут настраивать параметры профиля, делать ставки в разных валютах и участвовать в турнирах. Вход на портал открывает доступ ко всему ассортименту игр и мероприятий.
Вавада предлагает удобную мобильную версию сайта, совместимую с iPhone, Android и iPad. Мобильная версия позволяет играть в блэкджек, покер, рулетку и другие игры без необходимости скачивания приложения. Пользователи также могут получить приветственный бонус и наслаждаться игрой на ходу.
Vavada казино предоставляет пользователям возможность пройти регистрацию и начать играть в разнообразные игровые автоматы. Создание аккаунта на официальном сайте занимает всего несколько кликов. После регистрации открывается доступ к широкому спектру возможностей, включая выбор валюты (рубли, евро, доллары, злотые) и доступ к официальным играм, которые не доступны в демонстрационном режиме.
Vavada – популярное казино в странах СНГ, известное своим удобным интерфейсом и большим ассортиментом игр. Игроки могут сортировать игры по новинкам, жанрам, году выпуска и бонусам. Казино также предлагает возможность играть через мобильные устройства, обеспечивая удобный доступ к играм в любое время.
Официальный сайт Vavada предоставляет возможность пользователям играть в различные игры через 3D окно и доступен на русском языке. Рабочее зеркало Vavada позволяет обходить блокировки и играть из любой страны, предоставляя те же возможности и бонусы, что и основной сайт.
Vavada имеет лицензию от Кюрасао, что гарантирует безопасность и надежность игрового процесса. Использование генератора случайных чисел обеспечивает честность результатов. Казино придерживается политики ответственной игры, предоставляя возможность игрокам ограничивать время, проведенное за игрой, и блокировать учетную запись при необходимости.
Vavada предлагает более 1000 демонстрационных игр, включая видеослоты, карточные игры и лотереи. Игры распределены по жанрам, чтобы облегчить навигацию. Среди популярных игр: Sugar Rush, Golden Dragon Inferno, Rainbow Ryan и Gates Of Olympus. Казино сотрудничает с ведущими разработчиками программного обеспечения, такими как Betsoft, ELK Studios и NetEnt, чтобы предоставить пользователям лучший игровой опыт.
Бесплатная игра позволяет игрокам наслаждаться играми без риска для своих средств. Однако выигрыши, полученные в бесплатном режиме, нельзя обналичить. Тем не менее, демо игры предоставляют отличную возможность потренироваться и насладиться игровым процессом в непринужденной обстановке.